Looking at the Performer from a Hopfield point of view
 Linearized Performer attention
Linearized Performer attentionAbstract
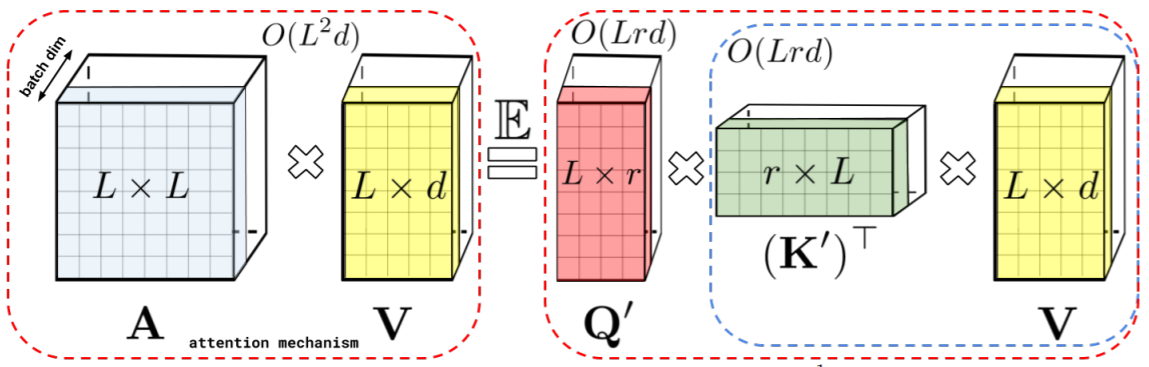
The recent paper Rethinking Attention with Performers constructs a new efficient attention mechanism in an elegant way. It strongly reduces the computational cost for long sequences, while keeping the intriguing properties of the original attention mechanism. In doing so, Performers have a complexity only linear in the input length, in contrast to the quadratic complexity of standard transformers. This is a major breakthrough in the strive of improving transformer models. In this blog post, we look at the Performer from a Hopfield Network point of view and relate aspects of the Performer architecture to findings in the field of associative memories and Hopfield Networks.
Type
Publication
10th International Conference on Learning Representations (ICLR), 2022 (Blogpost)